FaaS or Function as a Service also known as Serverless computing implementations are gaining popularity. Discussed often are the cost savings and each implementation’s relationship to the physical and network architecture of a specific platform or vendor. While many of the cost and infrastructure advantages of FaaS are compelling, it’s only one of many advantages. Below, I hope to demonstrate how easy it is to develop and deploy FaaS components into a custom Kubernetes cluster. The functions I develop are nearly all business logic, and I believe therein lies the advantage, high-density business logic. Functions can have a higher degree of focus directly on business logic and communication with other services. Functions can communicate with other functions, microservices or monoliths. In this article, I demonstrate this with Elasticsearch.
§2026 Update
Kubeless is gone. VMware archived it in 2021, the repo now lives under vmware-archive, and nothing has shipped since. The install steps below will not get you a working setup, and the runtime images are unmaintained. So this post is a museum piece for the tool, but the idea it argues for, dropping small functions into the same cluster as your monoliths and microservices, is more alive than ever. Here is where it went.
For FaaS on Kubernetes, look at Knative or OpenFaaS. Kubeless’s own creator moved on to Knative, which is the de facto serverless layer for Kubernetes now: HTTP autoscaling, scale to zero, and an eventing system. OpenFaaS and Fission are the other common picks. For exactly what this post does, a Python function behind an HTTP trigger, Knative Serving or OpenFaaS is the direct replacement.
The function itself talks to OpenSearch now. I moved off Elasticsearch (the why is on the Elasticsearch setup post). The elasticsearch and elasticsearch-dsl libraries pinned to 6.x here are long out of date, and the Elastic client now refuses to connect to OpenSearch on purpose. Use opensearch-py instead; the old opensearch-dsl-py was folded into it, so a single dependency gives you both the client and the query DSL. The raw from_dict query in the function carries over unchanged.
One smaller thing: the python3.6 runtime here is end of life. Whatever serverless layer you land on, target Python 3.11 or newer.
Archived: the original 2018 post follows. It is built on Kubeless, which VMware archived in 2021, so the walkthrough no longer produces a working setup. It is kept for the archives. Use the 2026 Update above for the current Knative or OpenFaaS path.
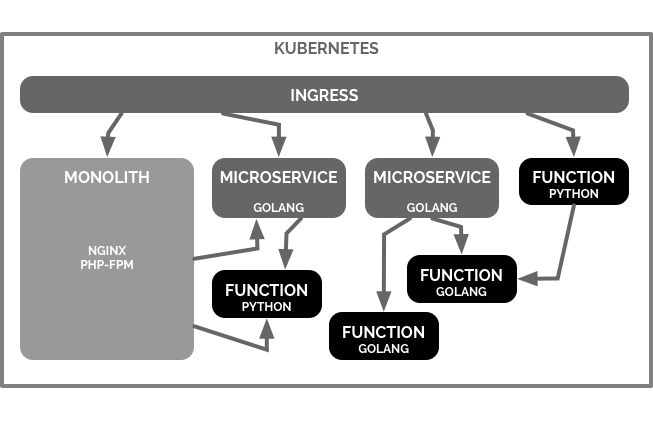
§Architecture
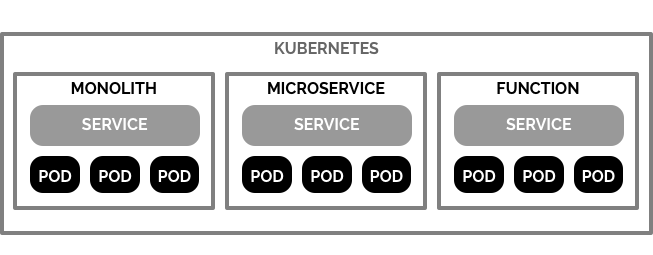
Lately, I have been seeing a trend of comparisons for choosing between developing applications with Monoliths, Microservices, or FaaS. I believe this comparison in some context, is flawed. Unless you are on a desert island and can only choose one implementation in which to develop your application, you still have a problem of definition. Even if you did have to limit your architecture to one concept, you would first need to define a standard of comparison, determining where a bloated Microservice is a monolith, or if a prewarmed FaaS is just a small Microservice. If you are following my point, they can all have a place regardless of definition, that is if the underlying platform can support them equally. All these concepts can work together seamlessly in one platform, by operating in networked containers, orchestrated by Kubernetes.
§Terminology
In this article I will use the term Function to describe a Kubeless Function. Kubeless is an implementation of FaaS Function as a Service also known as Serverless computing, Serverless, lambda, Google functions or even Nano Services.
§Motivation
While our industry sorts out the distinctions and vocabulary of these new architectures, please bear with me while I show you a simplified example, extracted from implementation I find successful. There are exciting and innovative ways to trigger and chain FaaS services. Implementations like Amazon’s Alexa and its use of AWS lambdas are one successful example. However in this article I demonstrate a basic implementation; the everyday needs of an HTTP API stack.
At this point most of my legacy systems are Monoliths; however they are containerized and live in the cluster as they would any hosting environment. I design most of my Microservices for generic or reusable functionality or more complex business logic not appropriate for pure functions. Functions are a great addition to data flow, and its pipeline between monoliths, microservices and other functions. Kubeless Functions give me the ability to quickly inject business logic at any point in the platform without significant architectural changes.
§Kubeless for FaaS
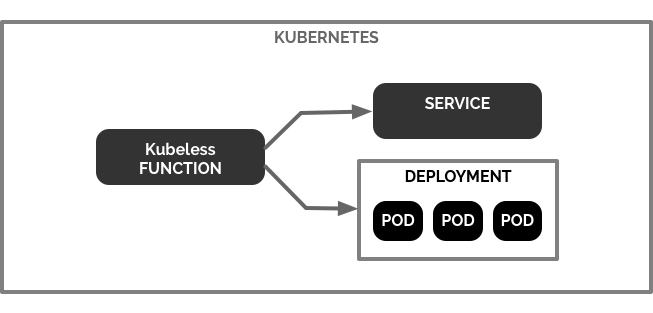
I appreciate the simplicity and elegance of Kubeless and its seamless integration into Kubernetes. Kubeless is an extension of the Kubernetes API and takes advantage of its stability and architecture. This integration with Kubernetes makes Kubeless incredibly easy if you are already familiar with Kubernetes.
Kubeless comes with its own CLI for interacting with Functions, providing commands such as kubeless function ls:
kubeless function ls -n the-project
NAME NAMESPACE HANDLER RUNTIME DEPENDENCIES STATUS
wx-stats the-project wx-stats.stats python3.6 python-dateutil==2.7.3 1/1 READY
elasticsearch==6.3.0
elasticsearch-dsl==6.2.1
However, due to Kubeless’ deep integration with Kubernetes, I often find myself executing kubectl commands simply out of habit:
kubectl get functions -n the-project
These commands are nearly synonymous, because Kubeless Functions are merely Kubernetes objects, or Custom Resources to be accurate, and many operations on them are as they would be with other resources in the cluster, like services, deployment or pods.
§Install Kubeless
Kubeless installs in the kubeless namespace by default and can be used to create functions in any namespace. I use RBAC for all my clusters, and if you are looking to set up a custom Kubernetes cluster, I recommend spending about an hour following my article Production Hobby Cluster.
Setting up Kubeless in your Production Hobby Cluster or hosted solution is easy, and the official installation instructions are clear.
If you have a Kubeless cluster already available and only need the CLI, then I suggest a brew install kubeless for the MacOs users.
§Toolchain and Local Development
Developing Kubeless Functions can be performed with the same tools as any other services. I build my Golang and Python functions with the commercial JetBrains IDEs Goland and PyCharm however free IDEs such as Visual Studio Code and Atom work great as well.
In this demo, my Functions are API endpoints that query Elasticsearch, check out my article Remote Query Elasticsearch on Kubernetes on how I port-forward Kubernetes Services for remote access. If your Kubernetes cluster needs set up for remote access, I suggest reading Kubernetes Team Access - RBAC for developers and QA.
§Python Function
The following Python code demonstrates a function that returns the last 24 hours of weather data for Los Angeles, specifically temperatures. The Elasticsearch query aggregates the data into buckets of two-degree Fahrenheit intervals for later use in histograms and further analysis.
The Elasticsearch DSL is an excellent library for working with Elasticsearch in Python. Although most of my Microservices are written in Golang, Python provides a tremendous number of mature and well-documented libraries for working with data.
§Script wx-stats.py
The following script wx-stats.py contains the function stats. Further down, I issue a Kubeless deployment using this file and the function name to call.
wx-stats.py:
#!/usr/bin/env python3
"""
Wx Stats from Elasticsearch
Local testing:
kubectl port-forward service/elasticsearch 9200:9200 -n the-project
HOST=localhost:9200 python ./wx-stats.py
"""
__author__ = "Craig Johnston"
__version__ = "0.0.1"
__license__ = "MIT"
import os
from elasticsearch import Elasticsearch
from elasticsearch_dsl import Search, connections
host = os.environ['HOST']
connections.create_connection(hosts=[host], timeout=20)
client = Elasticsearch()
s = Search(using=client)
def stats(event, context):
"""
Return wx stats
Uses the Python Elasticsearch DSL
https://elasticsearch-dsl.readthedocs.io/en/latest/search_dsl.html
"""
global s
res = s.from_dict({
"size": 0,
"aggs": {
"temps": {
"histogram": {
"field": "rxtxMsg.payload.currently.temperature",
"interval": 2
}
}
},
"query": {
"range": {
"@timestamp": {
"gt": "now-24h"
}
}
}
}).execute()
return res.to_dict()
if __name__ == '__main__':
"""
Mock event and context for development
See: https://kubeless.io/docs/kubeless-functions/
"""
event = {}
context = {}
# json is needed only for development and testing
# not necessary to import for Kubeless functions
import json
json_string = json.dumps(stats(event, context), indent=2)
print(json_string)
At this point I am not taking advantage of the Elasticsearch DSL, being flexible it allows me to write raw Elasticsearch queries. The Elasticsearch DSL is excellent for quick ports from other systems or experimenting while you are learning the syntax.
§Dependencies requirements.txt
Python’s pip package manager can generate and use a requirements.txt file to manage dependencies.
requirements.txt:
elasticsearch==6.3.0
elasticsearch-dsl==6.2.1
Ensure you meet these dependencies by issuing the pip install command:
pip install -r requirements.txt
The requirements.txt file is given to the Kubeless function on deployment and updates, to ensure the Kubeless runtime for Python contains the required packages.
§Local Development and Testing
The python script wx-stats.py can be run on the command line. In a separate terminal you need to port-forward the Elasticsearch service to your local workstation:
kubectl port-forward service/elasticsearch 9200:9200 -n the-project
At this point localhost:9200 responds as a local Elasticsearch would. In another terminal you can run the python script, when run as a script the function specified in the if name == ‘main’: conditional is executed, in this case stats(event, context).
I wrap the returned python dict in json.dumps to encode as json as Kubeless will when called in the cluster.
Running the following command sets the environment variable HOST to the location of the Elasticsearch service. Kubeless supports any number of environment variables specified in the function’s deployment.
HOST=localhost:9200 python ./wx-stats.py
§Deploy and Update
As of now, using the kubeless command is one of the easiest ways to deploy and update the Kubeless function.
kubeless function deploy wx-stats --runtime python3.6 \
--from-file wx-stats.py \
--dependencies requirements.txt \
--handler wx-stats.stats \
--env HOST=elasticsearch:9200 \
-n the-project
The kubeless command provides many options for a function deploy and update, along with help for any sub-command:
kubeless function deploy -h
While it is acceptable to avoid the kubeless command and write Kubeless Function resources in yml, I find it easy enough to add kubeless function update to my build scripts. Want the best of both imperative and declarative and configuration? Add kubeless function deploy and kubeless function update command to a Makefile.
§Testing
Now that we have deployed the Kubeless function, disconnect from port-forwarding the Elasticsearch service and test the new function by port-forward the new service pointing to it.
kubectl port-forward service/wx-stats 8080:8080 -n the-project
Now that I have port 8080 on my local workstation forwarding to port 8080 on the Kubernetes service wx-stats in the-project namespace, I use curl (or a web browser) to call the new wx-stats function.
curl -s localhost:8080 | jsonpp
Piping the curl output to jsonpp makes the JSON output a bit more readable for debugging.
{
"took": 61,
"timed_out": false,
"_shards": {
"total": 31,
"successful": 31,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 719,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"temps": {
"buckets": [
{
"key": 68.0,
"doc_count": 24
},
{
"key": 70.0,
"doc_count": 101
},
{
"key": 72.0,
"doc_count": 81
},
{
"key": 74.0,
"doc_count": 93
},
{
"key": 76.0,
"doc_count": 50
},
{
"key": 78.0,
"doc_count": 38
},
{
"key": 80.0,
"doc_count": 39
},
{
"key": 82.0,
"doc_count": 44
},
{
"key": 84.0,
"doc_count": 50
},
{
"key": 86.0,
"doc_count": 88
},
{
"key": 88.0,
"doc_count": 110
},
{
"key": 90.0,
"doc_count": 1
}
]
}
}
}
§Python Resources
Kubeless supports a variety of runtimes. In my case, most of my functions work with numbers, and It’s tough to beat Python in simplifying the areas of statistics, analytics, and machine learning. Using Kubeless means you don’t need to become an expert on writing large Python stacks. You can spend more time focusing on individual packages that help you develop your business logic directly. Python does a great job of supporting what I think is the real advantage of FaaS: high-density business logic.
- Elasticsearch DSL delivers a clean pythonic syntax for working with Elasticsearch.
- Python Data Essentials - Numpy provides a wide variety of options for working with numbers, extraordinarily powerful N-dimensional array objects in which we can perform linear algebra.
- Python Data Essentials - Pandas is a data type equivalent to super-charged spreadsheets. Pandas add two highly expressive data structures to Python, Series, and DataFrame.
§Port Forwarding / Local Development
Check out kubefwd for a simple command line utility that bulk forwards services of one or more namespaces to your local workstation.